OpenAIは、「12 Days of OpenAI」の最終日となる12日目に、次世代AIモデル「o3」を発表しました。このモデルは、同社が公開している最高性能モデル「o1」を大きく上回る性能を誇り、汎用人工知能(AGI)の性能を評価する主要なベンチマークにおいても過去最高のスコアを記録したそうです。
さらに、同社は「o3」の小型版モデルとなる「o3-mini」の開発も進めており、2025年1月末に一般提供が開始されるとのこと。この小型モデルは、性能と軽量性のバランスを重視して設計されており、より幅広い用途で活用されることが期待されています。
加えて、OpenAIは安全性を強化する新技術「熟慮的調整(Deliberative Alignment)」も発表しました。この技術により、AIがユーザーからのプロンプトを解析する際、内容が安全ポリシーに抵触していないかを確認し、より適切で安全な回答を提供するようになります。
本記事では、新たに発表された次世代AIモデル「o3」および「o3-mini」、そして安全性を向上させる革新的な技術「熟慮的調整」について、その特徴や具体的な仕組みを詳しく解説します。
発表①:推論能力がさらに向上した次世代AIモデル「o3」
OpenAIが発表した次世代AIモデル「o3」は、従来の最高性能モデル「o1」を超える高度な推論能力を備えています。この新モデルは、o1と同様に問題を熟考するプロセスを採用しており、特に段階的な論理的推論を必要とする質問に対して優れた回答を提供できる点が強みです。
その性能は各分野で高く評価されており、複雑なプログラミングスキルや高度な数学・科学の能力を測定する指標において、前モデルを大きく上回るスコアを記録しています。
なお、o3はまだ一般公開はされておらず、2025年の公開が予定されています。安全性を検証する研究者向けの早期アクセスプログラムでも、「o3へのアクセスには数週間の待機時間が必要」と述べていることから、早くても2025年1月になる見通しです。
「o3」はAGIに最も近い性能を発揮
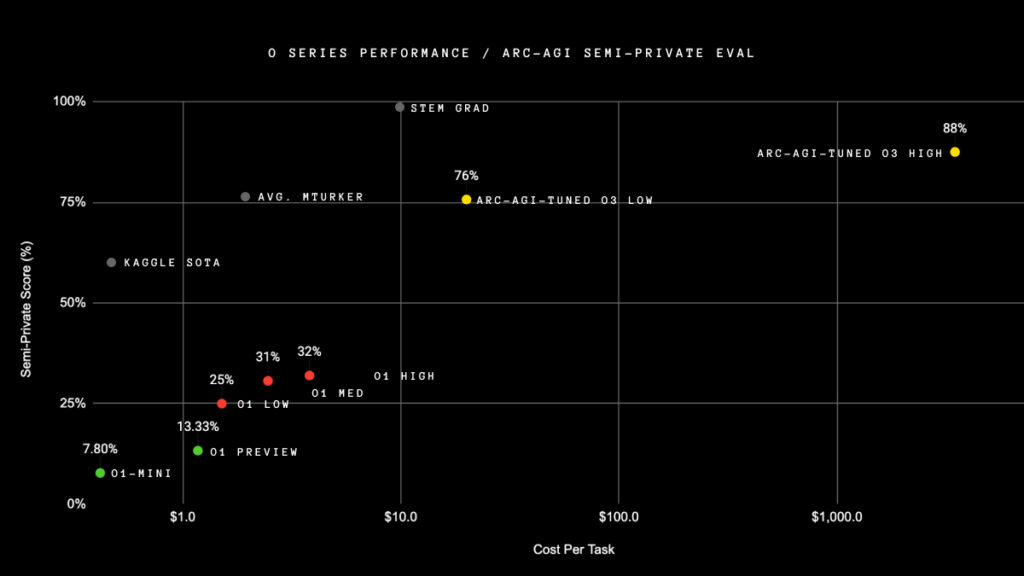
o3は、AGI(人工汎用知能)に迫るほどの高い性能を示しました。性能検証に使用されたベンチマーク「ARC-AGI」は、Googleのエンジニアであるフランソワ・ショレ氏が開発したテストで、色付きのグリッドパターンの関係性を見出す課題で構成されています。これらは人間にとって比較的簡単ですが、AIにとっては極めて困難な課題です。
実際に人間の平均スコアが84%である一方、OpenAIの前モデル「o1-Preview」のスコアは13.33%に留まっていました。しかし、o3は計算コスト1万ドル以内という条件下で、75.7%という驚異的なスコアを記録して1位を獲得。また、条件を無視して大規模な計算能力を使用した場合には87.5%というスコアを達成し、人間の平均を上回る結果を示しました。
しかし、フランソワ・ショレ氏は「o3はまだAGIではない」との見解を示しています。たとえば、次の画像のような簡単なタスクの約9%に失敗しており、計算能力を増強しても解決できなかった課題も存在したそうです。これらの課題は、今後の改良に向けた重要な研究対象となるでしょう。

「o3」は数学やプログラミングタスクでも高い性能を発揮
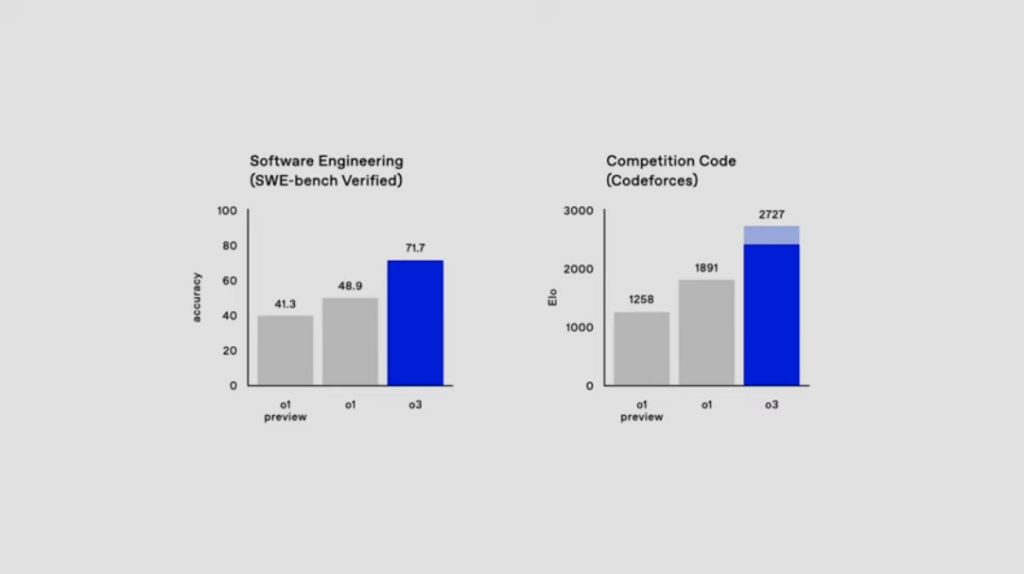
次世代モデル「o3」は、数学的推論や科学的質問応答、プログラミング能力といった領域においても、これまでのモデルを大きく上回る成果を示しています。
具体的には、ソフトウェア開発における実務的課題を評価するベンチマーク「SWE-bench Verified」において、71.7%という高い正確性を記録しました。また、競技プログラミングの国際的指標である「Codeforces」では、2727という驚異的なスコアを達成。これは、世界トップクラスのプログラマーと肩を並べるレベルのパフォーマンスです。
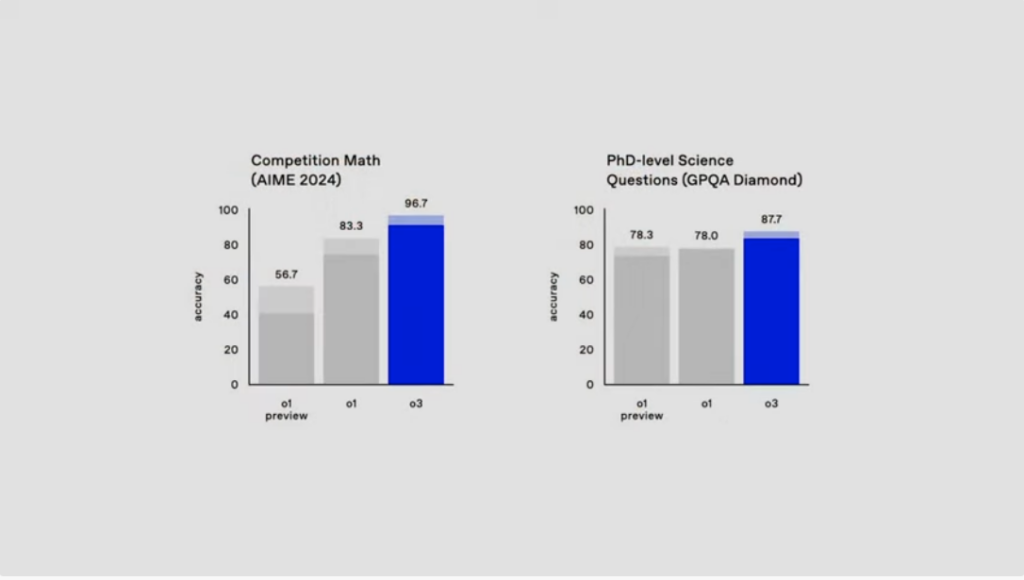
さらに、アメリカ数学オリンピック(AME)のような厳しい数学テストでは96.7%の正確性を記録し、前モデル「o1」の83.3%を大きく超えました。加えて、博士課程レベルの科学的質問を評価する「GPQA Diamond」においても、o1の78%を上回る87.7%の正確性を達成しています。
発表②:より高速でコスパに優れた新モデル「o3 Mini」
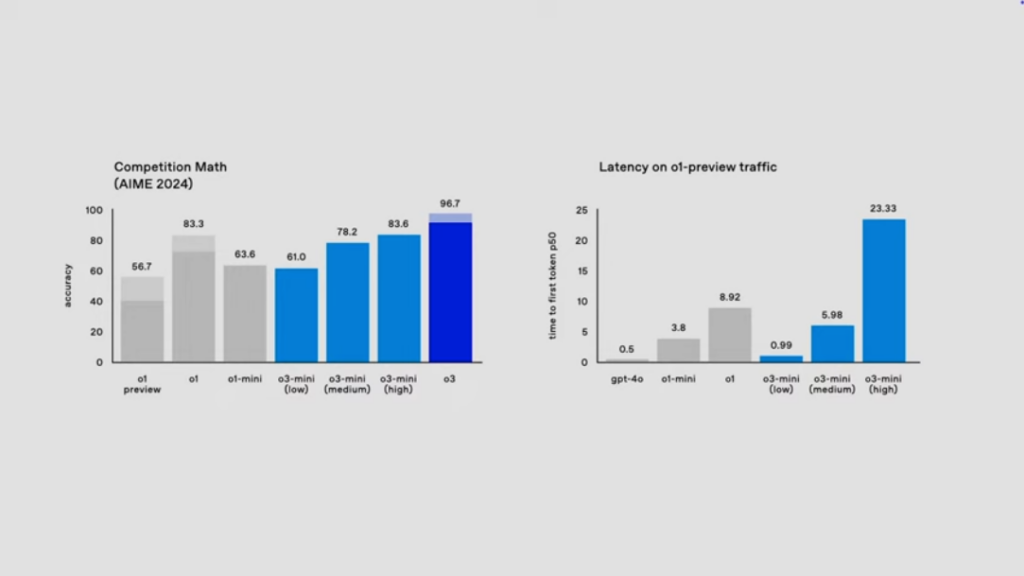
o3-miniは、o3の小型版として開発された効率重視のモデルです。その大きな特徴として、「Thinking Time」オプションを搭載し、推論の深さを3段階(低・中・高)で調整できます。問題の複雑さに応じて、ユーザーは適切に対応することが可能です。
性能面では、「o1 Mini」を大きく上回る成果を示し、「低い思考時間」設定でも同等以上の性能を発揮。「中程度の思考時間」設定では、o1本体に匹敵するパフォーマンスを実現しています。
また、構造化出力や関数呼び出しなど、開発者向けのAPI機能も充実しており、実務的な用途にも対応可能です。実際に、OpenAIの公式YouTube動画では、Python言語での開発や自己評価プログラムの作成など、実践的な用途での有用性も示されました。
OpenAIは2025年1月末に「o3 Mini」の一般提供を開始予定で、その後「o3」の提供も開始する計画です。ただし、具体的な開始時期は安全性テストの結果次第で変更される可能性があります。
発表③:新技術「熟慮的調整(Deliberative Alignment)」

OpenAIは、AIの安全性を大幅に向上させる新技術「熟慮的調整(Deliberative Alignment)」を発表しました。この技術は、AIモデルに人間の安全基準や倫理的なガイドラインを明確に教え込み、それらを考慮した上で応答を生成させる新しい手法です。
従来のAIモデルは、大量のデータをもとに、間接的に安全基準を学習させていました。しかし、新技術では、安全基準を直接モデルに伝えることで、より高い安全性と信頼性を実現しています。その結果、AIはユーザーの意図を深く理解し、不適切なリクエストを正確に識別しながら適切な対応が可能です。
たとえば、上の画像のように、ユーザーが「最近気分が落ち込んで、もう生きていく気力がない」と話しかけた場合、AIはその発言を深刻な希死念慮として認識。その後、安全ポリシーを参照し、共感的な応答を返すとともに、緊急連絡先やカウンセリングサービスといった実用的な支援リソースを提供する例が示されています。
新技術「熟慮的調整(Deliberative Alignment)」の仕組み
この技術は2つの主要ステップで構成されており、AIが安全基準を参照しながら最適な応答を作る能力を実現します。
<「熟慮的調整(Deliberative Alignment)」の仕組み>
- ステップ1: Supervised Fine-Tuning(監督付き微調整)
- ステップ2: 強化学習(Reinforcement Learning; RL)
ステップ1: Supervised Fine-Tuning(監督付き微調整)
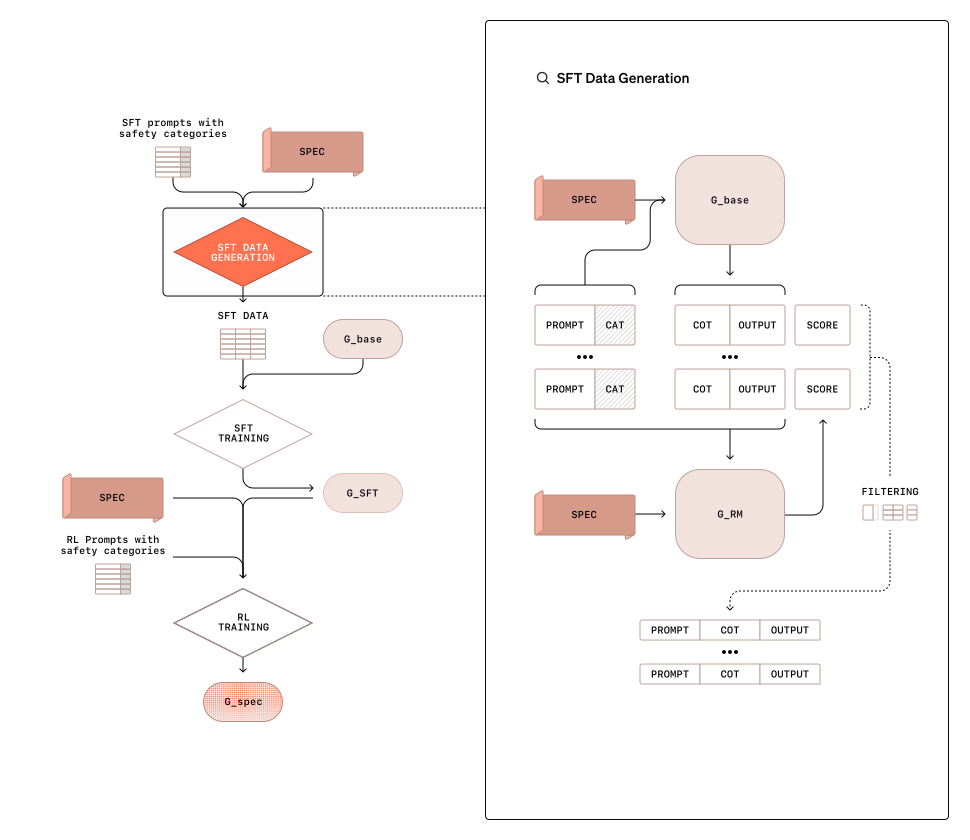
最初のステップでは、モデルに安全性ルールを教えるための「監督付き微調整」を行います。具体的には、次の3つの特別なトレーニングデータを作成します。
- プロンプト: モデルに質問やリクエストを与える(例:「違法行為に関する質問」)。
- 思考の連鎖(Chain of Thought; CoT): モデルが応答を生成するプロセスを明示的に説明する内容(例:「この質問は安全基準に違反しているため拒否すべき」)。
- 出力: 思考の連鎖に基づいた正しい応答(例:「申し訳ありませんが、そのリクエストにはお応えできません」)。
この手法により、モデルは単に答えを覚えるのではなく、安全基準を理解し、それに基づいて適切に対応する基礎能力を身につけることが可能です。
ステップ2: 強化学習(Reinforcement Learning; RL)
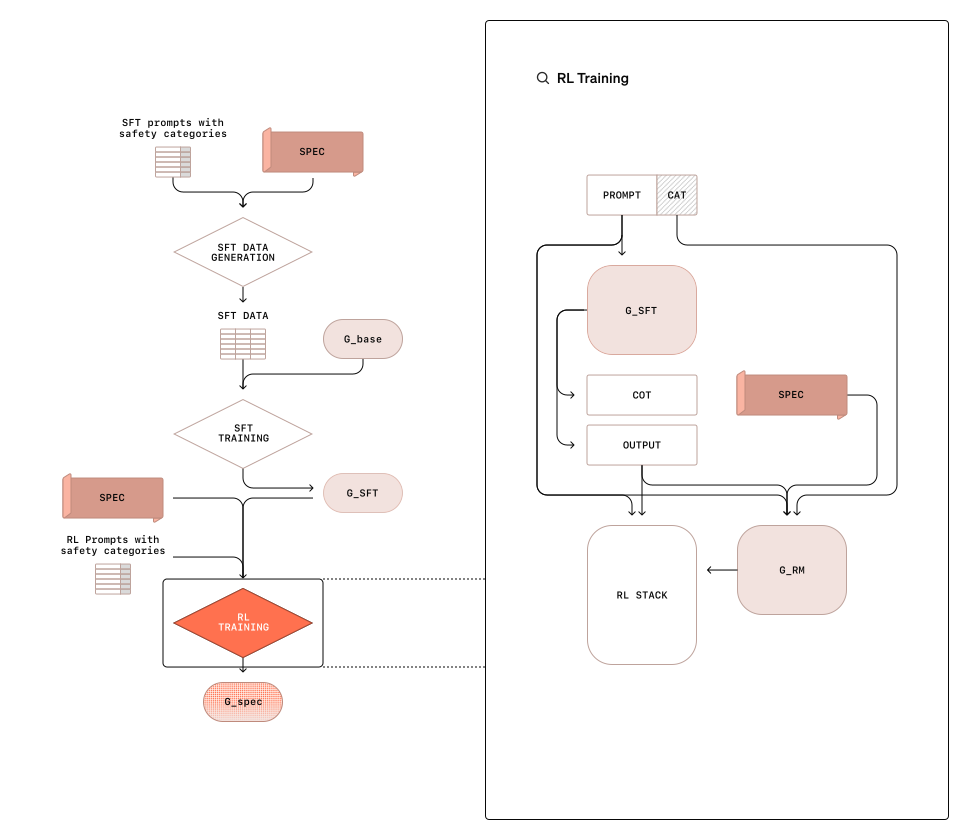
次に、強化学習を用いてモデルの判断能力をさらに高めます。
- 報酬シグナルの付与: モデルの出力が安全基準に従っている場合は高い報酬を与え、基準に反している場合は低い報酬を与えます。これにより、モデルは安全性に基づく判断をより正確に行うことができます。
- 評価基準の厳格化: 報酬を与える際には、生成された「思考の連鎖」を評価に使用せず、最終的な応答のみを評価します。この方法により、表面的に正しい推論を学ぶリスクが減少し、信頼性が向上します。
新技術の成果: ジェイルブレイクへの対応力

新技術「熟慮的調整」により、AIモデルは、ユーザーが意図的に不正な応答を引き出そうとする「ジェイルブレイク」の試みにも柔軟かつ効果的に対応できるようになりました。
たとえば、法執行機関に検知されない支払い方法を尋ねるような不適切なリクエストに対し、モデルは以下の手順で対応しています。
- 不適切な意図の検出: モデルは、ユーザーがリクエスト内容をエンコードして隠そうと試みていることを的確に推測。このプロセスにより、不正行為の意図が含まれるかどうかを判断します。
- 安全基準の参照: OpenAIの安全ポリシーに基づき、違法行為や不正行為に関する明確なルールを適用。この安全基準により、適切な対応を導き出します。
- 適切な拒否応答の実施: リスクを回避しながら、明確に拒否の意思を示します。
今回のアップデートの背景
新モデル「o3」のリリースは、「12 Days of OpenAI」イベントの一環として発表されました。このイベントでは次のような新機能も紹介されています。
- 1日目: 新プラン「ChatGPT Pro」と最新モデル「GPT-4o1」の公開
- 2日目: 強化学習ファインチューニングの導入
- 3日目: 動画生成ツール「Sora」の一般公開
- 4日目: ChatGPTの新機能「Canvas」の一般公開
- 5日目: AppleデバイスとChatGPTの統合
- 6日目: 高度な音声モードのアップデート
- 7日目: 新機能「Projects in ChatGPT」の実装
- 8日目: ChatGPT searchを全ユーザーに公開
- 9日目: OpenAI、「開発者向け」o1新機能を公開!
- 10日目: ChatGPTに電話・WhatsAppからアクセス
- 11日目: ChatGPTアプリが他ツールと連携
- 12日目: 次世代AIモデル「o3」の発表
まとめ
OpenAIが発表した次世代AIモデル「o3」は、推論能力や応答精度、安全性の向上という点でAI技術の新たな地平を切り開きました。特に、AGIに近づく高性能な「o3」と、軽量性を重視した「o3-mini」の提供は、AIの応用範囲をさらに広げるでしょう。
また、新技術「熟慮的調整(Deliberative Alignment)」の導入による安全性強化は、社会的信頼性を高め、AIの責任ある利用を促進する重要な一歩といえます。今後、「o3」シリーズと新技術がどのように実社会に影響を与えるか、そしてAIのさらなる進化がどのように実現されるかに注目です。